5 Steps to Add Security Foundations to your CI/CD Pipeline
Security practices that can help lay the foundations for increased security and visibility in your CI/CD pipeline.

A recent University Computer Science Graduate, I enjoy experimenting and learning by doing in my free time. This blog is a way for me to showcase skills and topics that I have learnt and encountered.
Security can be tough. Most mid to larger size companies will employ dedicated staff just to focus on security of systems and code. However, far too often are these teams understaffed or overworked. Thus, with a rising demand of security professionals, as well as the increase in popularity of DevOps, DevSecOps was born. DevSecOps aims to 'shift security left' by involving security, operations and dev teams to introduce security measures earlier on within the application lifecycle.
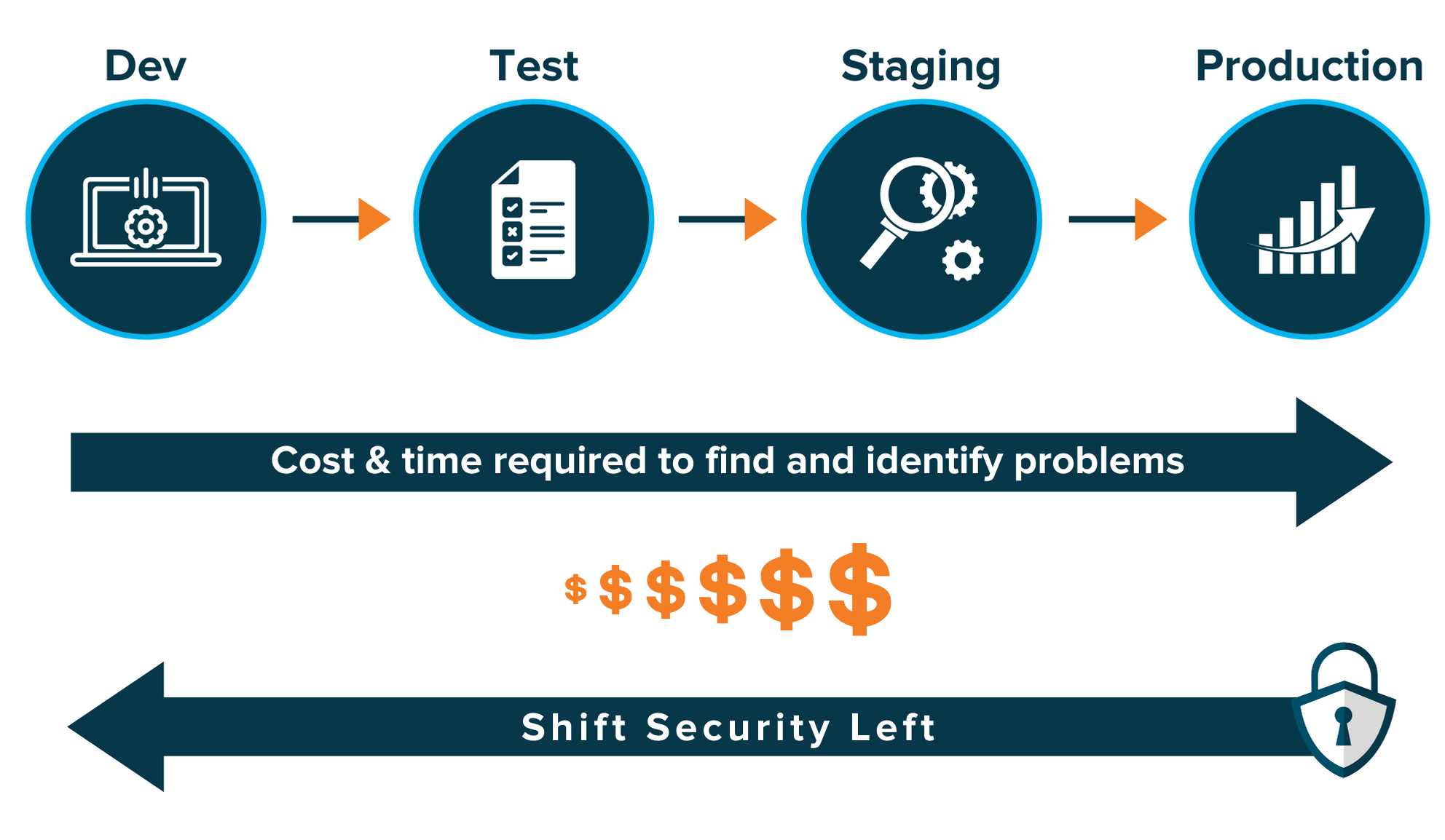
In this article, I'll illustrate 5 steps that you can use to start shifting security left, into the build phase of the application lifecycle, in a DevSecOps approach. Within, I focus on using GitHub actions as my choice of CI/CD platform, however these concepts can be lifted and applied to almost any other platform of your choice.
📝 Note: The aim of this article is to be a overview of 5 security practices you can incorporate into your CI/CD process, specifically when building your application. Every application, as well as runtime environment, is different, so this is not a guaranteed guide to security. This article serves as a starting point, where you can then carry out further research. I am not a security professional, however these are all steps I have used in either a professional or personal capacity.
🔐 Scanning for Secrets
When developing applications, there is often an abundance of credentials and secrets that are required within the project. These can range anywhere from AWS credentials for accessing their services (think DynamoDB or Kinesis streams), to API keys for third party API usage and even encryption secrets for entities such as JWT, Cookie and password encryption mechanisms. Due to the sensitive and potentially destructive nature (in the case of a malicious party gaining access to hosting environments/databases) of these secrets, they should not be committed into Git history. Files containing these secrets should be added to a repository .gitignore file to prevent this from happening.
Sometimes, however, these secrets manage to slip into code repositories. As this is a matter of when, not if, it is best to plan ahead and detect these as they are added to the repository, alerting for security visibility and tracking.
The following example makes use of gitLeaks, however other options include Whispers and Yelp's Detect-Secrets:
name: gitleaks
on: [ push , pull_request ]
jobs:
gitleaks:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
with:
fetch-depth: '2'
- name: gitleaks
uses: zricethezav/gitleaks-action@master
Should any secrets make it into the source code (or pre-existing secrets are discovered), the first step that should be carried out is to immediately disable the leaked key. This will prevent any malicious actor from compromising the associated account/service, giving you time to rotate the key and to remove the credential from the repository.
📝 Note: It is also worth noting that secret scanning can also be performed before commiting to a repository, using frameworks such as pre-commit or husky, which helps shift security even further left and would be a preferred solution. However everyone's development environment is different and as such this is not always an option, but it is worth digging into.
📄 Linting Code
Linting code is the process of statically scanning code for errors such as styling or syntactical issues, to better organize and secure your application. By ensuring code follows secure standards and is formatted in a sensible fashion, repositories become easier to maintain and to detect errors (such as memory leaks or other vulnerabilities) which could compromise your application. Having a standardized styling pattern can bring other benefits too, such as a better understanding/collaboration process on the codebase and an easier debugging experience. This is a good, quick first scan that can be run to help increase security and efficiency within your pipeline, however it is not always mandatory.
In this snippet, Hadolint, a Dockerfile linter, is used to ensure standards are maintained. One such standard that Hadolint searches for, is the versioning of applications installed within containers from package managers. This is an important, lesser known tip that helps to keep maintainability, preventing Docker builds from breaking between machines because of an unknown package version upgrade. For alternatives, check out the documentation for GitHub's Super-Linter, which houses linters for various programming languages.
name: Hadolint
on: [ push, pull_request ]
jobs:
hadolint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: hadolint
uses: hadolint/hadolint-action@v1.5.0
with:
dockerfile: Dockerfile
😒 Scanning for Known Vulnerable Components
Scanning for known vulnerable components, aka insecure dependencies, is a big step in reducing the potential attack vector within your application. With some applications requiring hundreds, if not thousands of dependencies (once factoring the entire dependency tree), a compromise within one could leave your application wide open to attack. The good thing, however, is that there are several tools that can be used to identify any insecure dependencies within your application, with some even generating the fixes required for you.
Dependabot is a tool directly integrated into GitHub code repositories, allowing for a configurable dependency scanning experience, with scans being able to run for multiple different package managers across multiple languages, all in the same repository. Upon detecting of a vulnerable dependency, Dependabot will then automatically open a pull request against the codebase, bumping the dependency to a fixed/secure version, without the need for a developer to carry out the upgrade.
# Basic set up for two package managers
version: 2
updates:
- package-ecosystem: "github-actions"
directory: "/"
schedule:
interval: "weekly"
labels:
- "actions"
- "dependencies"
- package-ecosystem: "npm"
directory: "/"
schedule:
interval: "daily"
labels:
- "npm"
- "dependencies"
open-pull-requests-limit: 10
If, instead, you would prefer a tool that you can use locally, as well as between different CI/CD providers (e.g. if in a larger, segmented organization), then I would recommend checking out Dependency Check, as it is backed by the Open Web Application Security Project (OWASP).
🔎 Run SAST Scans
Static Application Security Testing, or SAST, is similar running a code linter. It scans your codebase, looking for known or custom patterns and reporting on the findings. However, where SAST differs is that instead of looking for potential styling or syntax errors, scans are run to detect insecure code. These scans commonly use pre-defined rules from industry professionals to run, with some options going the extra mile to provide links to resources explaining the risk of the issues detected. By nature, SAST scans are not context aware, so if you have addressed the security concerns to do with detected snippets elsewhere, the scan will still report a false-positive result. However, these false-positives can be an eye opener into the architectural decisions as to why these vulnerable code-snippets are in the code base, regardless of the security measures put in place. After all, even after adding layers of security, should you really be calling dangerouslySetInnerHTML? 🤔
One such SAST tool is Semgrep. Semgrep allows you to hand-pick the rules to run on the code, or alternatively to use a pre-defined collection of rules (rulesets) tailored to specific languages and/or security topics. With over 1400 rules, at the time of writing, these can be explored here.
name: Semgrep
on:
# Scan changed files in PRs
[ pull_request ]
# Scan all files on branch
push:
branches:
- "main"
jobs:
semgrep:
runs-on: ubuntu-latest
# Skip any PR created by dependabot to avoid permission issues
if: (github.actor != 'dependabot[bot]')
steps:
- uses: actions/checkout@v2
- name: semgrep
uses: returntocorp/semgrep-action@v1
with:
auditOn: push # Never fail the build due to findings on push
config: >-
p/security-audit
p/nodejsscan
p/expressjs
env:
SEMGREP_TIMEOUT: 300
🤔 Collect Information and Act on it
Finally, after performing any of these steps the most important thing to do is to act on the findings. This is crucial to ensuring the security of applications, as without acting on disclosures the whole process becomes a zero sum equation. If you find a leaked secret, or an insecure dependency, fixing it could be the difference between the application carrying on as normal and data loss/breach of GDPR - which could incur eye-watering fines if this occurs with Personally Identifiable Information (PII).
📎 TL;DR
In summary, some of the key ways of introducing security (along with stability and visibility) into CI/CD can be achieved by introducing the following to your procedures and pipelines:
- Scan for hard-coded secrets
- Lint for inconsistent syntax and code styling
- Search out insecure dependencies to reduce your surface area of attack
- Test for insecure code within your repository with SAST tools
- Act on your findings
There is always more that can be done to improve security (such as environment scanning, DAST scanning, etc), however by introducing some basics, you are setting off in a good direction.

